



أدهشت الملايين .. واتساب يضيف ميزة جديدة طال انتظارها
أطلق تطبيق واتساب واحدة من أكثر الميزات التي انتظرها المستخدمون، إذ أصبح بالإمكان إجراء واستقبال الم...





تدين الجمعية الوطنية للمجلس الانتقالي الجنوبي العربي، بأشد عبارات الإدانة والاستنكار، واقعة اقتحام مبنى اتحاد نقابات عمال الجنوب في مديرية المعلا بالعاصمة عدن، وما رافقها من استخدام مفرط للقوة لإخراج...

أدان مجلس المستشارين للمجلس الانتقالي الجنوبي العربي، بأشد العبارات واقعة اقتحام مبنى اتحاد نقابات عمال الجنوب في مديرية المعلا بالعاصمة عدن، وما رافقها من استخدام مفرط للقوة لإخراج رئيس الاتحاد وموظف...
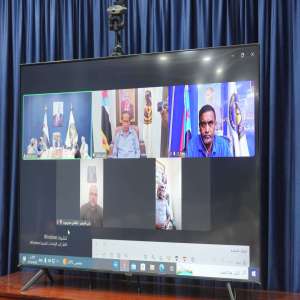
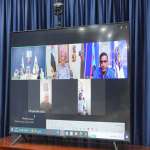
عقد الرئيس القائد عيدروس قاسم الزُبيدي، رئيس المجلس الانتقالي الجنوبي العربي، اليوم الإثنين، عبر الاتصال، اجتماعا بأعضاء هيئة الرئاسة الجدد، الذين جرى تعيينهم بموجب القرار رقم (3) لسنة 2026، الصادر يو...

أصدر الرئيس القائد عيدروس قاسم الزُبيدي رئيس المجلس الانتقالي الجنوبي العربي، اليوم السبت، الموافق 25 يوليو القرار رقم (4) لعام 2026، وتضمن القرار المواد الآتية:مادة(1): يُعين كلٌ من الآتي أسماءهم في...
أطلق تطبيق واتساب واحدة من أكثر الميزات التي انتظرها المستخدمون، إذ أصبح بالإمكان إجراء واستقبال الم...
أطلقت منصة يوتيوب مجموعة من الأدوات والخصائص الجديدة الموجهة لمتابعي البودكاست، في خطوة تعكس سعيها ا...

تستعد منصة "واتساب" لإطلاق واحدة من أبرز الميزات التي انتظرها المستخدمون لسنوات، وهي دعم "أسماء المس...

أكدت شركة أبل الأمريكية رسميا استحواذها على شركة "كيو.إيه آي" (Q.ai) الناشئة، التي تتخذ من تل أبيب م...
